Simplifying Infrastructure Deployment on AWS with GitOps and GitHub Actions - Part 2


In the first part of this blog series, we learned how to create infrastructure as code in Terraform. Now that we have defined the infrastructure in Terraform, we will attempt to automate its deployment through a CI platform. While numerous CI platforms are available, we will go with GitHub Actions. It is closely integrated with the GitHub version control system. It has quite a good collection of actions created by the community and in the GitHub marketplace, which can be used within our workflows.
To get started with GitHub Actions, you can follow the tutorials here: https://docs.github.com/en/actions/quickstart
When developing the workflow we aim to be able to deploy the infrastructure in a secure and scalable manner.
We also follow the same principles as the previous post while defining the CI pipeline. To reiterate, they are:
Keep it simple
Keep it generic and follow the principle of 'do not repeat yourself' (DRY)
Keep it scalable
Here is the directory structure within our .github folder where action workflows are defined.
├── .github
│ ├── actions
│ │ └── terraform_action
│ │ └── action.yml
│ └── workflows
│ └── terraform.yml
Creating Reusable Actions
We create a reusable action within the folder .github/actions/terraform_action. https://docs.github.com/en/actions/using-workflows/reusing-workflows mentions the advantages of reusing the workflows and how to do it.
In the reusable workflow, we define the following steps:
Configure AWS Credentials
Set up a specific version of Terraform on the runner
Create a terraform plan
Based on the input, one can apply the plan, destroy the infrastructure, or take no action.
Authenticating with AWS
The recommended way to authenticate with AWS within GitHub Actions is to use OIDC. OIDC or OpenID Connect protocol lets any third-party application authenticate and verify the end user's identity. This article explains how to configure your IAM role to use OIDC. An important thing to note here is to construct your IAM policy following the principle of least privilege to be as specific as possible. Even in your IAM trust policy, providing a full path to your repository and branch ( if applicable ) is always recommended.
Create Terraform Plan
The Terraform plan provides a preview of upcoming infrastructure changes, serving as a crucial step to anticipate and avoid any unwanted or destructive alterations to our systems.
Deploy the infrastructure
In this step, the infrastructure gets deployed in AWS. This step is invoked based on the value provided to the input variable operation
Destroy the infrastructure
This step is invoked in the value provided for operation input variable is destroy. It is valuable when creating infrastructure for testing purposes and there is a need to tidy up and remove resources once the tests are concluded.
Here are the contents of .github/actions/terraform_action
name: "Terraform Action"
descriptions: "Terraform operations"
inputs:
operation:
description: "Whether the job should apply after plan"
required: true
default: 'plan'
iam_role_arn:
description: "IAM Role ARN for OIDC authentication"
required: true
domain_path:
description: "name of the domain who records needs to be deployed"
required: true
aws_region:
description: "Region where state bucket and dynamodb table exists"
required: true
runs:
using: "composite"
steps:
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{inputs.iam_role_arn}}
aws-region: ${{inputs.aws_region}}
- uses: hashicorp/setup-terraform@v2
with:
terraform_version: "1.6.4"
- name: Terraform Plan
working-directory: ${{inputs.domain_path}}
run: |
set -x
if [ ${{ inputs.operation }} = "plan" ]; then
terraform init -reconfigure
terraform validate
terraform plan -lock=false -input=false
fi
shell: bash
- name: Terraform apply
working-directory: ${{inputs.domain_path}}
run: |
if [ ${{ inputs.operation }} = "apply" ]; then
echo "Running terraform apply..."
terraform --version
terraform init -reconfigure
terraform apply -auto-approve -input=false
else
echo "Bypassing Terraform apply..."
fi
shell: bash
- name: Terraform destroy
working-directory: ${{inputs.domain_path}}
run: |
if [ ${{ inputs.operation }} = "destroy" ]; then
echo "Running terraform destroy..."
terraform --version
terraform init -reconfigure
terraform apply -auto-approve -input=false -destroy
else
echo "Bypassing Terraform apply..."
fi
shell: bash
Detecting Changes in the repository
Deploying every infrastructure defined in the repository each time a change occurs wouldn't be ideal, especially when dealing with many Route 53 hosted-zones and records. Hence we define our workflow in such a way that it can determine what exactly has changed and apply the changes to only that infrastructure. This makes it easier to scale.
We define a job changed_files to determine which files have changed. As discussed in the first segment of this blog series, Infrastructure as Code (IAC) comprises two main components: modules and templates, each accompanied by variables. Changes to modules will impact all Route 53 hosted zones and their associated records, whereas changes to individual templates will only affect the specific hosted zone they are associated with. Here we are using a third-party action called as tj-actions/changed-files . The documentation for this action can be found at https://github.com/marketplace/actions/changed-files. The code snippet to determine which files have changed is shown below:
#! /bin/bash -x
if [[ ${{steps.changed-files.outputs.modules_any_changed}} == 'true' || ${{steps.changed-files.outputs.workflows_any_changed}} == 'true' ]]; then
echo "Adding all hosted zones"
domain_zones=()
for file in $(ls records); do
domain_zones+=(records/$file)
done
domain_paths=$(jq -c -n '$ARGS.positional' --args ${domain_zones[@]})
echo "$domain_paths"
echo "domain_paths={\"domain\": $domain_paths}" >> $GITHUB_OUTPUT
elif [ ${{steps.changed-files.outputs.domainpaths_any_changed}} == 'true' ]; then
changed_domain_zones=()
for file in ${{steps.changed-files.outputs.domainpaths_all_changed_files}}; do
echo "$file was changed"
echo "Directory is $(dirname $file)"
changed_domain_zones+=($(dirname $file))
done
echo "changed_domain_zones ${changed_domain_zones[@]}"
unique_changed_domains=($(printf "%s\n" "${changed_domain_zones[@]}" | sort -u))
echo "Unique changed domains ${unique_changed_domains[@]}"
domain_paths=$(jq -c -n '$ARGS.positional' --args ${unique_changed_domains[@]})
echo "domain_paths={\"domain\": $domain_paths}" >> $GITHUB_OUTPUT
echo "$domain_paths"
else
echo "domain_paths={\"domain\": []}" >> $GITHUB_OUTPUT
fi
As evident in this snippet, we capture the output in JSON format. This proves beneficial in the subsequent job responsible for deploying the infrastructure.
Deploying the Infrastructure to AWS
Having identified the domains requiring updates, we proceed by generating a Terraform plan in the next step. Depending on the targeted environment, we then initiate the deployment of the infrastructure. As we've opted for Route 53 domains and records in our infrastructure, we can straightforwardly designate the environment as 'production.' However, when dealing with other infrastructure components such as VPCs, EC2 instances, and more, we may need to configure multiple environments, such as development, staging, and so on.
As the initial step, we generate individual Terraform plans for each of the domains requiring updates. Since these domains are independent of each other, we have the flexibility to execute these update jobs simultaneously in parallel. We use a matrix strategy to define this job as we can use the number of the changes domains determined in the previous job to define the degree of parallelism here.
Here is the definition of the job
terraform_plan:
runs-on: ubuntu-latest
needs: changed_files
if: needs.changed_files.outputs.if_changed_files == 'true'
strategy:
max-parallel: 1 # assuming they should run in series
matrix: ${{fromJSON(needs.changed_files.outputs.domains)}}
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: terraform-plan
id: terraform-plan
uses: ./.github/actions/terraform_action
if: ${{needs.changed_files.outputs.if_changed_files}} == 'true'
with:
operation: plan
iam_role_arn: arn:aws:iam::195368226277:role/gitops-terraform-demo-role
domain_path: ${{matrix.domain}}
aws_region: "us-east-1"
As we can see in the job definition we generate a Terraform plan for each of the changed domains.
The next step is to deploy the changes to AWS. Here we use the 'Environment' feature provided by GitHub Actions. Environments in GitHub Actions provide us with a way to define different rules for different environment targets. This helps us prevent untested changes from getting deployed to the production environment. GitHub also provides deployment protection rules. One can use this to include a manual approval step and to restrict deployment from only certain branches. For example, we might want to restrict any deployments to the production environment only from the main branch of the repository.
Here is a screenshot of the environment setting for the repository used in this blog post.
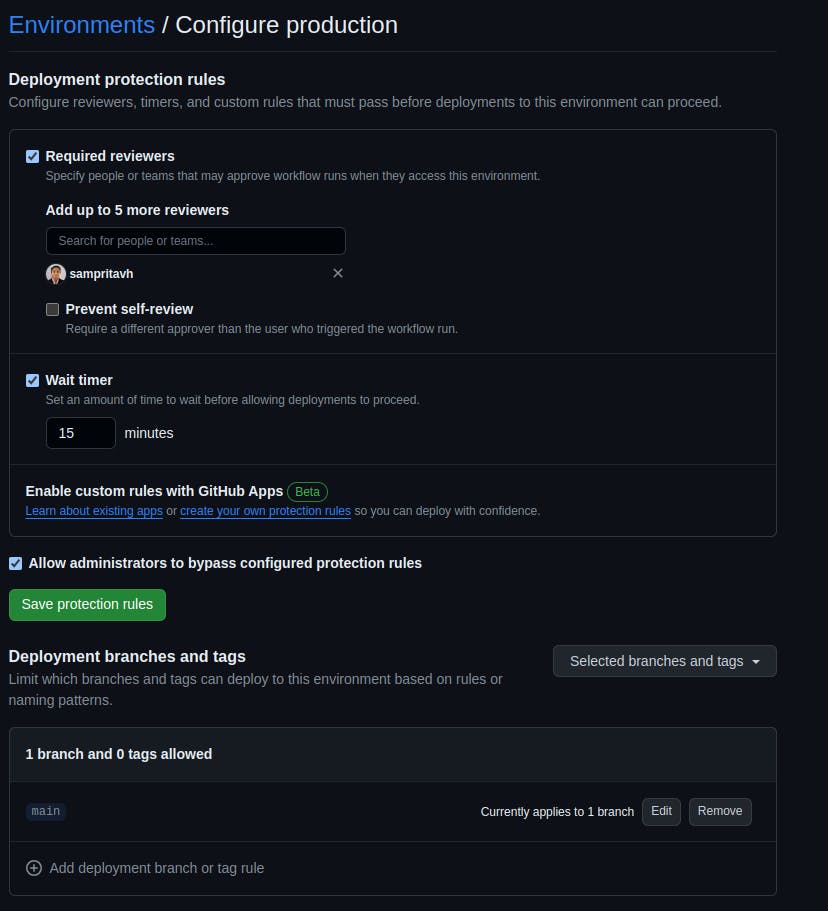
The job definition of 'deployment' is similar to that of terraform_plan except
We specify the environment as
productionWe pass the value
applyto the variableoperationwhen invoking the re-usable action.
Here is the code snippet for the deployment job.
deployment:
runs-on: ubuntu-latest
needs: [changed_files,terraform_plan]
if: needs.changed_files.outputs.if_changed_files == 'true'
strategy:
max-parallel: 3 # configure this to your convenience
matrix: ${{fromJSON(needs.changed_files.outputs.domains)}}
environment:
name: production
url: https://github.com
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: terraform-deploy
id: terraform-deploy
uses: ./.github/actions/terraform_action
if: ${{needs.changed_files.outputs.if_changed_files}} == 'true'
with:
operation: apply
iam_role_arn: arn:aws:iam::195368226277:role/gitops-terraform-demo-role
domain_path: ${{matrix.domain}}
aws_region: "us-east-1"
Cleaning up the infrastructure ( Optional )
The last step is the clean-up of the infrastructure. This can be an optional step and we can control it through environment variables. For example, one might want to clean up the infrastructure after testing in a non-production environment to save costs. The cleanup job is similar to deployment except that the operation will have the value destroy.
A typical workflow run is shown below:

The reference code can be found at https://github.com/sampritavh/terraform-deployment-demo
This is a demo workflow and it can be easily extended to other infrastructure or any other deployment patterns.